The WCMA Tricma (pronounced WickMa TrickMa) is an umbrella project to hold the various parts of the collections, graphql api and dashboard projects. There's some common information that's useful to have about all of them and this is the place to put it, as well as tracking issues that don't neatly fit into individual parts.
The general idea is that we build a system that allows us to extract data from various data sources, be that CSV, JSON, XML files or a number of TMS system. Then allow that data to be combined and served from a common api source. The technology we've chosen means it looks something like this...
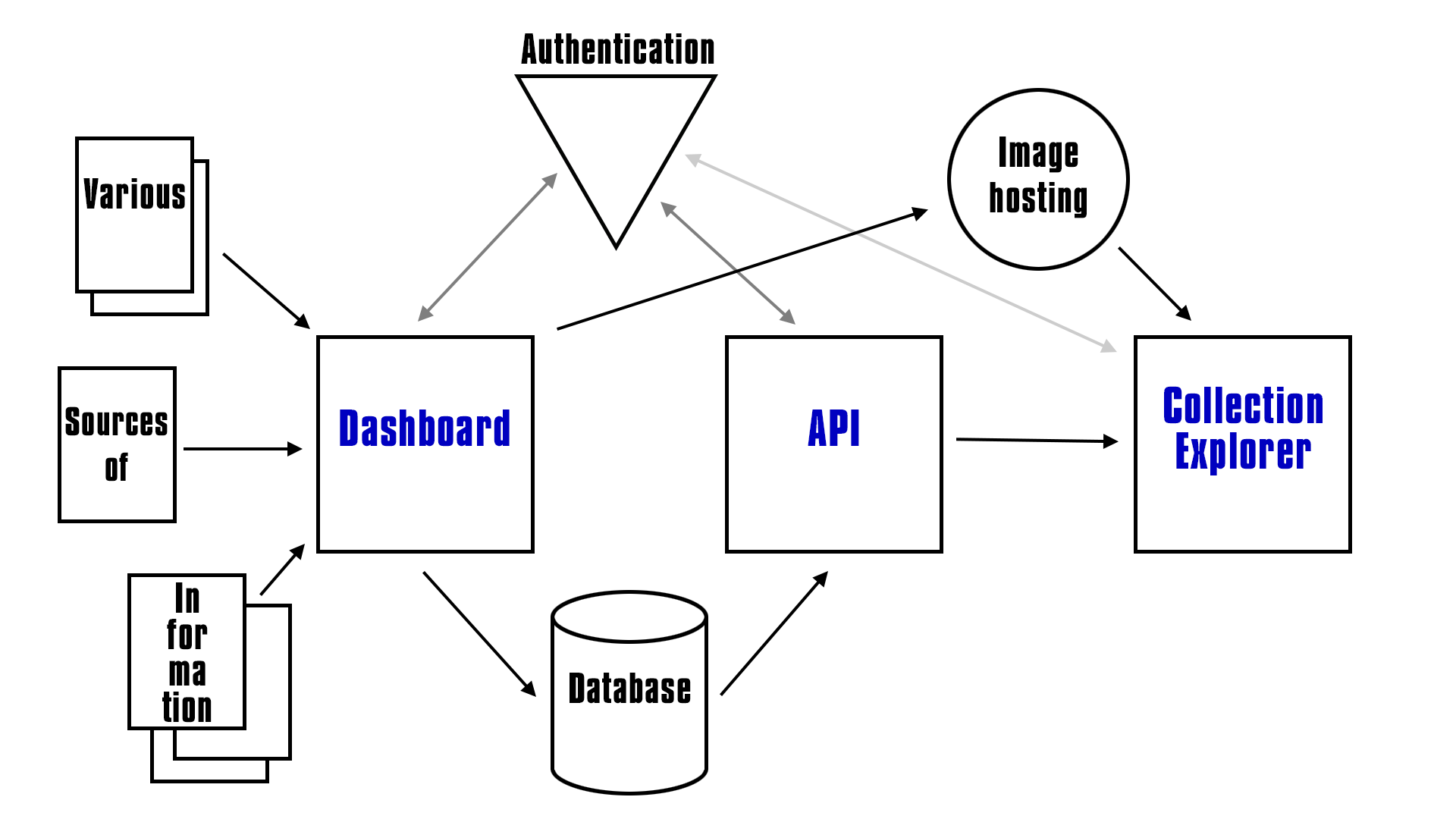
The three main items in blue are the three repos you can find here on wcma:
-
The is the part of the project that allows to upload the data to the data store, upload images to the image store, set user accounts and other general administration tools such as logging and automating the data uploading.
It also acts as a place for developers who wish to use the GraphQL endpoint to register for a developer API key and read the documentation.
-
This is the API that allows third part developers (with an API key from the dashboard) to make calls to the API, which returns information about the data we have stored.
In this case the technology we have chosen is GraphQL
-
The Collection "Spelunker"
This is an example app, that shows how a developer may interact with the API and display the results.
In the above overview we've used general terms for the parts that are external to our three main repositories, they are in turn;
For us these consist of a single TMS system and some well defined JSON files.
We are using Auth0 to handle our user login and user roles.
Our external datastore is ElasticSearch, in our case hosted on elastic.co with a Kibana management panel.
We are uploading and hosting the images with Cloudinary.
Is mainly a Node + Express + express-handlebars application with a bunch of other stuff, see the repo for more details.
Is a graphQL server built using Node + Express + express-graphQL, which backs onto the ElasticSearch database, see the api repo for more.
Is a node + react web app which pulls data from the graphQL server.
Before cloning the three repos you should probably set up accounts for at least...
...because you will need both of those before you can do anything.
You should also set up a local version of ElasticSearch and Kibana to store any data, see the dashboard for more information.
Once that is set up you should follow the instructions on the dashboard to start consuming data, and then follow the instructions on the API to expose the data as a handy GraphQL endpoint.
If you want to test the endpoint finally clone and run the collection.
General issues that span all parts of the project just be added in Issues and tracked in the Project. For example things like "Should we move the datastore to SQlite?" would live here because both the dashboard and the API are involved. If the decision to move was made then we'd place that as two individual tasks on each repo.